Growth Paths for the Coming Superintelligence
In
Login if you are already registered
(votes: 5, rating: 5) |
(5 votes) |

PhD in Technical Sciences, Founder, Aigents, Architect, SingularityNET
In the year and a half since the previous article was published, the technology of large language models (LLM) based on generative pretrained transformers (GPT) has advanced so much that an increasing number of scientists and developers are beginning to believe that a general, strong and even superhuman intelligence (artificial general intelligence, AGI) could arrive within just a few years. One striking example is the recent high-profile paper by Leopold Aschenbrenner from OpenAI (the developer of ChatGPT). Its title, “Situational Awareness,” is a military term, which obviously suggests that this book is supposed to be studied in military and political circles in the first place. Indeed, along with asserting that the advent of superintelligence is imminent within the next three years, the author calls on the U.S. leadership to take immediate action to ensure total U.S. dominance in the “AI race,” with severe restrictions on the capabilities to develop such technology in other world “centers of power,” including classification of all further AI efforts in the U.S. Although there is still a wide range of predictions in the research community as to when AGI will emerge, the strategic importance and prospects of AGI technology as a tool of national and military domination was also highlighted in last year’s book “The Age of AI: And Our Human Future” by Google co-founder Eric Schmidt and former U.S. Secretary of State Henry Kissinger. This article examines how close AGI really is and what remains to be done to achieve it.
Modern large language models based on transformers like ChatGPT allow us to solve the problem that Alan Turing set over 50 years ago and to solve it “in earnest” this time, using machine learning on massive amounts of text data. However, if we look closely at the definition of AGI given by its authors, ChatGPT still falls short of general intelligence. While it indeed generates optimal text responses in the context of information from the text corpus used in training and a given prompt, and does so quite fast, learning to adapt to new environments or operating within limited computing resources are out of the question. Training is a one-off process—it takes over a month to train ChatGPT on a high-performance GPU cluster and would take over 300 years on a single card. As a result, we cannot yet talk about minimizing power consumption either—running models like ChatGPT today requires as much energy as cryptocurrency mining. So what else is missing from LLM/GPT for achieving AGI?
The main obstacle and limitation for the widespread adoption of LLM/GPT-based systems is the problem of so-called “hallucinations,” where in the lack of sufficient training data in the context of a given query, the system tries to generate something that appears correct in terms of grammar and training dataset but is inadequate in substance. Larger models tend to have fewer hallucinations, while smaller ones have more hallucinations, but the problem needs to be somehow solved in all of them.
For over 50 years, two paradigms of AI development were pitted against each other: the “neural network” (sub-symbolic, associative or connectionist) and “symbolic” (semantic or logical) approaches. It might seem that in recent years LLM/GPT has finally showcased the triumph of the former paradigm and spared us the need to use semantics and ontologies. But it turns out that ontologies, rebranded as “knowledge graphs,” are not going away, as they are still necessary to help neural networks not to generate inadequate responses or at least pick a more or less accurate response from a set of inadequate or random ones. This begs the question: where do these ontologies come from? They have to be built somehow and by someone. If we want to root the outputs of transformers and large language models in structured knowledge, we are back to square one in the race between the two approaches, because this structured knowledge has to come from somewhere. These knowledge graphs are currently compiled manually, and there are no high-quality fully-automated solutions in sight—on the market or in academic publications—though work is underway, even based on the use of LLM/GPT. This remains and open challenge, but it will clearly be one of the next frontiers we will push back in the foreseeable future.
Next, let us recall the definition of AGI as the ability to learn in a changing environment, where the input data and surroundings are altering very quickly. Unfortunately, large language models today are not able to do this, as they are trained on a finite, although large, dataset, after which it is very difficult to change the knowledge embedded in the system. While we naturally can tweak the system’s responses by changing the prompt, the model is static nonetheless. If we want to fine-tune the model using a large, new dataset that covers new or expanded range of tasks, we will have to start from scratch (think of a month and a half of training on a cluster or 300+ years on a single GPU).
Finally, there is another important issue that goes beyond the definition of AGI but seems critical to its practical application. If we want to entrust general or strong artificial intelligence systems with solving issues related to human life, health, safety and security, we must have something that is called “trustworthy” AI. This implies the ability not only to explain a decision made by AI ex post facto, as in “explainable AI” solutions, but also to interpret the structure and content of the “learned” AI model itself to understand what knowledge the model has. We need to be able to analyze and verify the structure of the knowledge learned by the model, and one way to make the structure of this knowledge verifiable or analyzable is to express it in terms of formal semantics, ontologies or what is now known as “knowledge graphs”—everything we describe as “symbolic AI.” We call this kind of intelligence “interpretable AI.”
We may be moving toward understanding how the human brain works from a psychological perspective, as suggested by Nobel Prize winner Daniel Kahneman. His cognitive model says that human thinking and behavior depend on two systems. These are “system 1”—“associative,” essentially a “neural network”—and “system 2”—“logical,” essentially a “symbolic” system. The first one learns slowly but offers quick “intuitive responses.” The second one quickly absorbs new information and delivers “logical” conclusions, but is not very fast in finding them, as it is necessary to “think through” everything logically. Solutions can be found both ways. To be more precise—if not by one method, then by the other, whichever is faster or more reliable at a given moment. We can make intuitive or logical predictions or decisions in either case. The key point, however, is that “system 2” is interpretable because it operates with clear and logically interpretable concepts. Conversely, “system 1” is not interpretable because, although it can learn from big data and generate “intuitive” responses, it takes extra effort to extract structured knowledge from it. If we manage to create a neuro-symbolic architecture (like the one proposed by the author in 2022), we will be able, on the one hand, to interpret and verify the knowledge stored in neural networks by extracting it and, on the other hand, to upload structured knowledge obtained and verified by experts into neural network models—equipping them with new skills and enabling decision-making in subject areas previously unknown to them, without expensive training on massive datasets.
Is superintelligence just around the corner?
In the year and a half since the previous article was published, the technology of large language models (LLM) based on generative pretrained transformers (GPT) has advanced so much that an increasing number of scientists and developers are beginning to believe that a general, strong and even superhuman intelligence (artificial general intelligence, AGI) could arrive within just a few years. One striking example is the recent high-profile paper by Leopold Aschenbrenner from OpenAI (the developer of ChatGPT). Its title, “Situational Awareness,” is a military term, which obviously suggests that this book is supposed to be studied in military and political circles in the first place. Indeed, along with asserting that the advent of superintelligence is imminent within the next three years, the author calls on the U.S. leadership to take immediate action to ensure total U.S. dominance in the “AI race,” with severe restrictions on the capabilities to develop such technology in other world “centers of power,” including classification of all further AI efforts in the U.S. The paper was recently discussed at a workshop of the Russian-language AGI developer community (video recording and transcript of the event). Although there is still a wide range of predictions in the research community as to when AGI will emerge, the strategic importance and prospects of AGI technology as a tool of national and military domination was also highlighted in the book “The Age of AI: And Our Human Future” by Google co-founder Eric Schmidt and former U.S. Secretary of State Henry Kissinger published in 2022. The book examines how close AGI really is and what remains to be done to achieve it.
Let us start once again with the definition of AGI, as laid out over 20 years ago from similar perspectives by Ben Goertzel, Shane Legg, Pei Wang and Peter Voss. According to the definition, AGI is the ability to achieve complex goals in complex environments, under resource constraints, by adapting to changes in those environments and learning new behaviors in new environments. In mathematical terms, it can be paraphrased as the capacity to solve arbitrary problems in a multi-parameter optimization environment, where the number of both input and output parameters is quite large, all parameters can change arbitrarily, while availability and consumption of time and energy are among the parameters and must be minimized. In other words, the system must self-learn to find optimal solutions under any new environments, balancing multiple alternative choices with constraints on decision-making time and computing power. Does an LLM/GPT technology like ChatGPT meet these requirements?
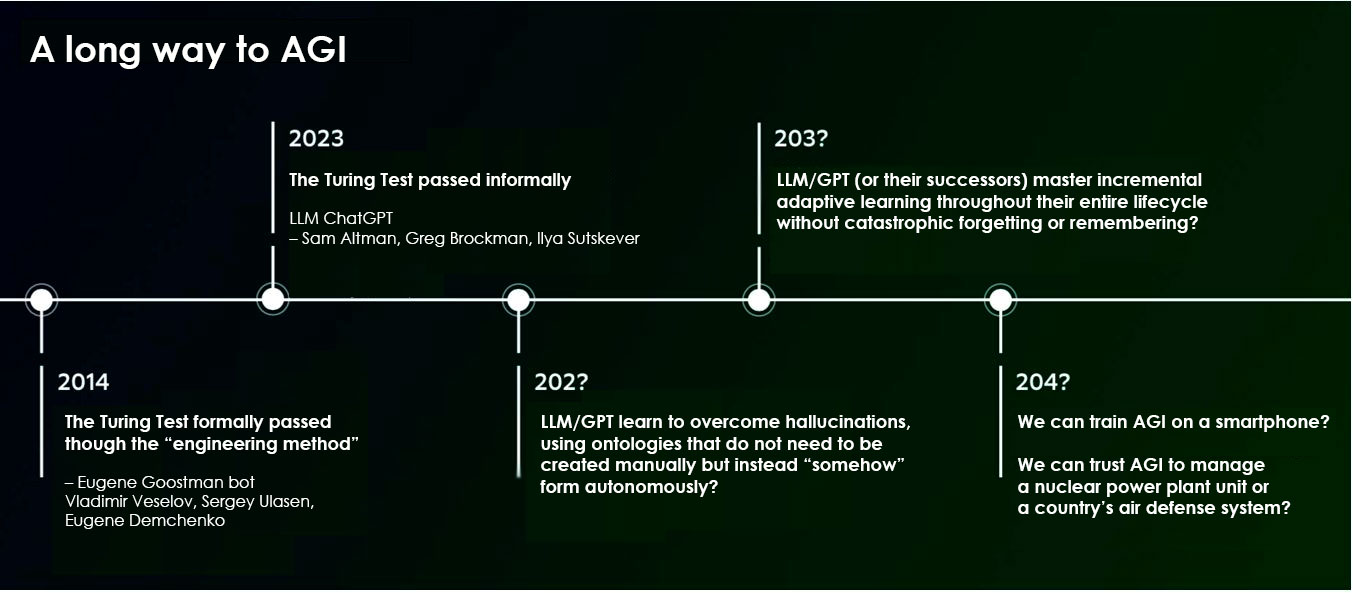
Estimated timeline for AGI as per the author’s overview
Alan Turing once devised a test for “human-like conversational artificial intelligence”, now known as the Turing Test, which was passed 10 years ago by a computer program developed by a Russian-Ukrainian team of Vladimir Veselov, Sergey Ulasen and Eugene Demchenko. Interestingly, as previously noted, the Eugene Goostman program, which passed the test, was not AGI by any standards described in the definition above and did not even contain what is now called “machine learning.” Instead, it was simply a computer software program purposefully designed to pass this test—a detailed description of this technology was presented by one of the developers at the AINL-2014 conference. The heated debate in the research community following this event led to a near-unanimous consensus that the Turing Test cannot be considered an adequate benchmark of artificial intelligence, precisely because it can be passed simply by a “programmed algorithm.”
Today, 10 years later, we finally see that the Turing Test has been passed not formally, but substantively. Modern large language models based on transformers like ChatGPT allow us to solve the problem that Alan Turing set over 50 years ago and to solve it “in earnest” this time, using machine learning on massive amounts of text data. However, if we look closely at the definition of AGI given by its authors, ChatGPT still falls short of general intelligence. While it indeed generates optimal text responses in the context of information from the text corpus used in training and a given prompt, and does so quite fast, learning to adapt to new environments or operating within limited computing resources are out of the question. Training is a one-off process—it takes over a month to train ChatGPT on a high-performance GPU cluster and would take over 300 years on a single card. As a result, we cannot yet talk about minimizing power consumption either—running models like ChatGPT today requires as much energy as cryptocurrency mining. So what else is missing from LLM/GPT for achieving AGI?
What’s the remedy for hallucinations?
The main obstacle and limitation for the widespread adoption of LLM/GPT-based systems is the problem of so-called “hallucinations,” where in the lack of sufficient training data in the context of a given query, the system tries to generate something that appears correct in terms of grammar and training dataset but is inadequate in substance. Larger models tend to have fewer hallucinations, while smaller ones have more hallucinations, but the problem needs to be somehow solved in all of them. Different companies address this issue in different ways, one form or another, relying on so-called ontologies, semantic networks or “knowledge graphs.”
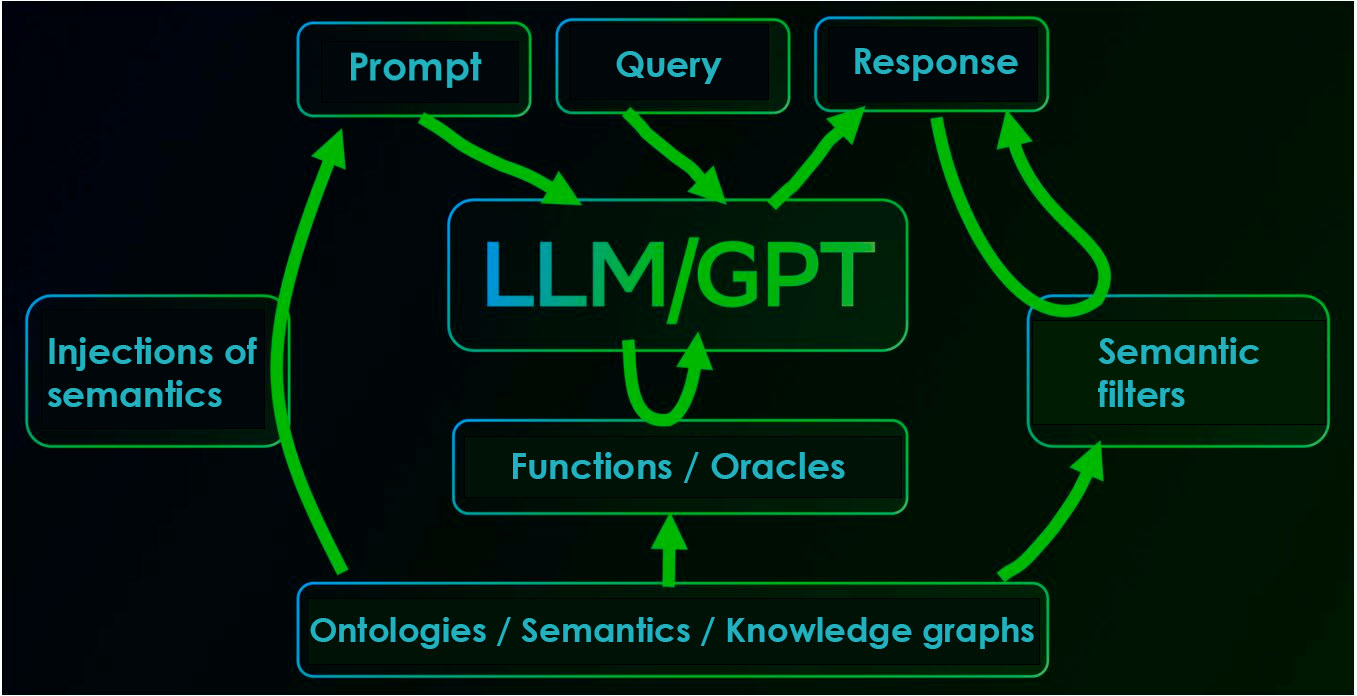
Fighting LLM/GPT hallucinations at Palantir.
Palantir, a market leader in AI solutions for business reconnaissance, computer security and a range of military applications in the U.S. and perhaps in the entire world, faced this problem as soon as it moved to practical use of LLM/GPT technology. The company had to look for a solution based on ontologies or “knowledge graphs” to minimize neural network “hallucinations.” Ontologies are used in Palantir at various stages of LLM/GPT application: during training, by embedding “semantic markup” into the test data; during prompt refining, by embedding relevant “knowledge graph” fragments into the context of the query; and during the filtering of generated responses for adequacy, using semantic graphs specific to the subject area. And these “knowledge graphs” are created ... manually.
A paradox arises. For over 50 years, two paradigms of AI development were pitted against each other: the “neural network” (associative or connectionist) and “symbolic” (semantic or logical) approaches. It might seem that in recent years LLM/GPT have finally showcased the triumph of the former paradigm and spared us the need to use semantics and ontologies. But it turns out that ontologies, rebranded as “knowledge graphs,” are not going away, as they are still necessary to help neural networks not to generate inadequate responses or at least pick a more or less accurate response from a set of inadequate or random ones. This begs the question: where do these ontologies come from? They have to be built somehow and by someone. If we want to root the outputs of transformers and large language models in structured knowledge, we are back to square one in the race between the two approaches, because this structured knowledge has to come from somewhere. These knowledge graphs are currently compiled manually, and there are no high-quality fully-automated solutions in sight—on the market or in academic publications—though work is underway, even based on the use of LLM/GPT. This remains and open challenge, but it will clearly be one of the next frontiers we will push back in the foreseeable future.
Solving this issue requires, among other things, the development of automated technology for segmenting sequences into meaningful “symbols” at different levels of perception—both for texts and audio or video streams in natural languages (symbol, morpheme, word, sentence) and for arbitrary sequences such as DNA/RNA chains in molecular biology or event logs in computerized process control systems, etc.. In the author’s recent work, for example, a close relation was discovered between the “meaningfulness” of Russian, English and Chinese dictionaries and the minimization of entropy and density of information compression in text corpora of these languages. A culture-agnostic technology for text segmentation was also developed based on these findings. This could presumably enable both the structuring of natural language texts and the identification of information-relevant events in other application domains, all without the need for costly GPU computing, as well as the creation of initial symbol sets for further construction of knowledge graphs. Another study demonstrated how, with appropriately structured texts at level of words and punctuation, it is possible to build both taxonomies of concepts used in a language and basic grammatical relations between these concepts. We think it necessary to continue working in this direction and are doing so through our open-source project “Aigents.”
Adaptation to changes and life-long learning?

From GPT to AGI: Takeoff or Landing?
Next, let us recall the definition of AGI as the ability to learn in a changing environment, where the input data and surroundings are altering very quickly. Unfortunately, large language models today are not able to do this, as they are trained on a finite, although large, dataset, after which it is very difficult to change the knowledge embedded in the system. While we naturally can tweak the system’s responses by changing the prompt, the model is static nonetheless. If we want to fine-tune the model using a large, new dataset that covers new or expanded range of tasks, we will have to start from scratch (think of a month and a half of training on a cluster or 300+ years on a single GPU).
According to neurophysiology, human cognition involves both so-called short-term memory (STM) and long-term memory (LTM), with the former storing the immediate “operational context” and the latter holding long-term “life experience.” It is believed that behaviorally relevant current experience acquired in the context of STM is gradually transferred to LTM. Nothing like this happens in LLM/GPT architectures—the “operational context” that includes the “prompt” is overwritten in the user session memory once it exceeds the size limit and is not transferred to the underlying model. The only movement in this direction in the world of LLM/GPT is reinforcement learning with human feedback (RLHF), where dialogue logs from all user sessions are reused in the next cycle of model training, which takes from over a month to over 300 years, as we already know.
To achieve a fully functional general or strong AI, we need to make sure it can automatically adapt to changing environments. In other words, the system should be able to learn continuously throughout its entire lifecycle, right “out of the box.” However, most of the reinforcement learning solutions available today rely to some extent on a variation of back-propagation, which is used in deep neural networks. These are different forms of Q-learning or Deep Q-learning algorithms. This type of learning is very expensive and very slow. At the same time, a joint project between Sber and Novosibirsk State University (NSU) managed to demonstrate how decision-making systems can be built using a combination of the following four mathematical methods. The first is the logical-probabilistic method, essentially probabilistic logical inference based on semantic models. The second it is the method of probabilistic formal concepts, which allows the construction of ontological systems or systems of relations of and between objects, attributes as well as other objects based on fuzzy data—in other words, probabilistic semantic models. The third is the task-driven approach, which helps apply both of these methods to certain subject areas by specifying in a structured way the goals, objectives and operational environment for the subject area. The fourth is the theory of functional systems, developed by P. K. Anokhin, which both explains how living organisms adapt to changing environments based on the theory of functional systems, and, according to the mathematical model by E. E. Vityaev of NSU, allows these principles to be applied to build adaptive learning systems. This mathematical concept was used to design a cognitive architecture for decision-support systems, with practical applications across several domains.

Interpretable mathematical methods for building AGI as per research by Sber and NSU.
The best of both worlds: neuro-symbolic integration!
Finally, there is another important issue that goes beyond the definition of AGI but seems critical to its practical application. If we want to entrust general or strong artificial intelligence systems with solving issues related to human life, health, safety and security, we must have something that is called “trustworthy” AI. This implies the ability not only to explain a decision made by AI ex post facto, as in “explainable AI” solutions, but also to interpret the structure and content of the “learned” AI model itself to understand what knowledge the model has. We need to be able to analyze and verify the structure of the knowledge learned by the model, and one way to make the structure of this knowledge verifiable or analyzable is to express it in terms of formal semantics, ontologies or what is now known as “knowledge graphs”—everything we describe as “symbolic AI.” We call this kind of intelligence “interpretable AI.”

The concept of neuro-symbolic integration combining the “associative” (left) and “logical” (right) cognitive systems as per the author’s research.
It should also be noted that in many practical applications, we should be able to run AGI systems without relying on the computing power from clusters with hundreds of thousands of specialized GPUs provided by a single commercial company. We must be able to solve business, public, state and human tasks, if not on an end user’s smartphone, then at least on the corporate server of a company located within the jurisdiction of a respective state. Companies, government agencies and citizens alike should not run the risk of being left without computing infrastructure hosted in a “foreign” cloud due to the volatility of today’s geopolitical environment. This is where cheaper and more computationally efficient “symbolic AI” methods, including those based on probabilistic logic and the formal concepts mentioned above, could potentially help.

Malicious Use of AI and Challenges to Psychological Security: Future Risks
So where are we headed? We may be moving toward understanding how the human brain works from a psychological perspective, as suggested by Nobel Prize winner Daniel Kahneman. His cognitive model says that human thinking and behavior depend on two systems. These are “system 1”—“associative,” essentially a “neural network”—and “system 2”—“logical,” essentially a “symbolic” system. The first one learns slowly but offers quick “intuitive responses.” The second one quickly absorbs new information and delivers “logical” conclusions, but is not very fast in finding them, as it is necessary to “think through” everything logically. Solutions can be found both ways. To be more precise—if not by one method, then by the other, whichever is faster or more reliable at a given moment. We can make intuitive or logical predictions or decisions in either case. The key point, however, is that “system 2” is interpretable because it operates with clear and logically interpretable concepts. Conversely, “system 1” is not interpretable because, although it can learn from big data and generate “intuitive” responses, it takes extra effort to extract structured knowledge from it. If we manage to create a neuro-symbolic architecture (like the one proposed by the author in 2022), we will be able, on the one hand, to interpret and verify the knowledge stored in neural networks by extracting it and, on the other hand, to upload structured knowledge obtained and verified by experts into neural network models—equipping them with new skills and enabling decision-making in subject areas previously unknown to them, without expensive training on massive datasets.
An attentive reader may have spotted a paradox: earlier in this article, “symbolic methods” were described as cheap and efficient, and then, with reference to Daniel Kahneman, it was suggested that “logical” thinking, represented by his “system 2”, is slower and more costly than “associative” thinking. The solution to the paradox is seen in the fact that in the human brain “logical” thinking (“system 2”) is built upon the mechanisms of “associative” logic (“system 1”)—much like modern add-ons to LLM/GPT models such as “chains of thought” attempt to enhance their ability to “reason logically.” The application of “logical chains” in pure form based on the above-mentioned “knowledge graphs” using “probabilistic logical inference” could prove much more efficient when realized on modern computing architectures, than when done on natural and artificial neural networks.
A broad range of topics related to the development of general or strong AI is regularly discussed at online seminars hosted by the Russian-language AGI developer community.
(votes: 5, rating: 5) |
(5 votes) |
New technological breakthroughs in AI: outlook, opportunities, threats and risks
Malicious Use of AI and Challenges to Psychological Security: Future RisksHumanity is entering another industrial revolution, and technological patterns are changing


